
ABSTRACT
Mass media sources, specifically the news media, have traditionally informed us of daily events. In modern times, social media services such as Twitter provide an enormous amount of user-generated data, which have great potential to contain informative news-related content. For these resources to be useful, we must find a way to filter noise and only capture the content that, based on its similarity to the news media, is considered valuable. However, even after noise is removed, information overload may still exist in the remaining data—hence, it is convenient to prioritize it for consumption. To achieve prioritization, information must be ranked in order of estimated importance considering three factors.
First, the temporal prevalence of a particular topic in the news media is a factor of importance, and can be considered the media focus (MF) of a topic. Second, the temporal prevalence of the topic in social media indicates its user attention (UA). Last, the interaction between the social media users who mention this topic indicates the strength of the community discussing it, and can be regarded as the user interaction (UI) toward the topic.
We propose an unsupervised framework—SociRank—which identifies news topics prevalent in both social media and the news media, and then ranks them by relevance using their degrees of MF, UA, and UI. Our experiments show that SociRank improves the quality and variety of automatically identified news topics. We are taking live stream data’s from the twitter. Then we have to recommend the top news to the user
EXISTING SYSTEM
Media Focus Estimation: To estimate the MF of a TC, the news articles that are related to TC are first selected. This presents a problem similar to the selection of tweets when calculating UA. The weighted nodes of TC are used to accurately select the articles that are genuinely related to its inherent topic. The only difference now is that instead of comparing node combinations with tweet content, they are compared to the top k keywords selected from each article. Hashtags are of great interest to us because of their potential to hold the topical focus of a tweet. However, hashtags usually contain several words joined together, which must be segmented in order to be useful. This problem, occured in our existing work.
The segmented terms are then tagged as “hashtag.” To eliminate terms that are not relevant, only terms tagged as hashtag, noun, adjective or verb are selected. The terms are then lemmatized and added to set T, which represents all unique terms that appear in tweets from dates d1 to d2.
DISADVANTAGES
Hard to find a way to filter news from noisy High computational demand prioritize.
PROPOSED SYSTEM
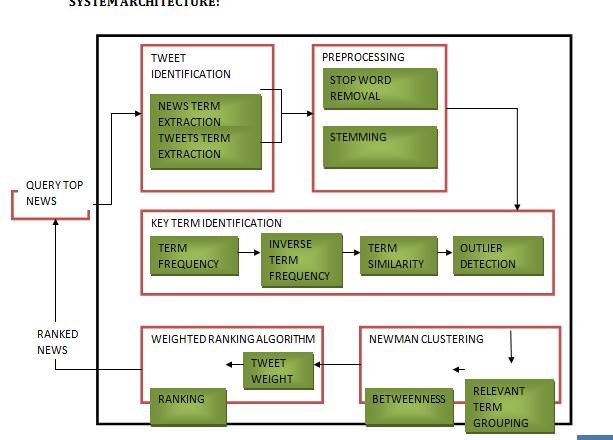
The goal of our method—SociRank—is to identify, consolidate and rank the most prevalent topics discussed in both news media and social media during a specific period of time. To achieve its goal, the system must undergo four main stages.
1) Preprocessing: Key terms are extracted and filtered from news and social data corresponding to a particular period of time.
2) Key Term Graph Construction: A graph is constructed from the previously extracted key term set, whose vertices represent the key terms and edges represent the co-occurrence similarity between them. The graph, after processing and pruning, contains slightly joint clusters of topics popular in both news media and social media.
3) Graph Clustering: The graph is clustered in order to obtain well-defined and disjoint TCs.
4) Content Selection and Ranking: The TCs from the graph are selected and ranked using the three relevance factors (MF, UA, and UI). Initially, news and tweets data are crawled from the Internet and stored in a database. News articles are obtained from specific news websites via their RSS feeds and tweets are crawled from the Twitter public timeline. A user then requests an output of the top k ranked news topics for a specified period of time between date d1 (start) and date d2 (end).
ADVANTAGES
We can find a way to filter noise and only capture the news.
We can filter the news based on topic
Main use potential to improve the quality and coverage of news recommender system.
ALGORITHM:
1. Preprocessing
2. Stopwords
3. Stemming
4. TF/IDF
5. New Man’s Algorithm
SYSTEM ARCHITECTURE:
SYSTEM REQUIREMENTS:HARDWARE REQUIREMENTS:
System : Pentium IV 2.4 GHz.
Hard Disk : 40 GB.
Floppy Drive : 1.44 Mb.
Monitor : 15 VGA Colour.
Mouse : Logitech.
Ram : 512 Mb.
SOFTWARE REQUIREMENTS:
Operating system : Windows XP/7.
Coding Language : JAVA/J2EE
IDE : Netbeans 7.4
Database : MYSQL
For more details about Projects : http://ieeeprojectcentre.in/java-application-projects-in-chennai.php
CONTACT US
1Croreprojects Center,
Door No : 68 & 70, No : 172, Ground Floor,
Rahaat Plaza ( Opp. of Vijaya Hospital ),
Vadapalani. Chennai-600026.
Call / WhatsApp: 9751800789 / 7708150152
Email ID: 1croreprojects@gmail.com
REFERENCES
D. M. Blei, A. Y. Ng, and M. I. Jordan, “Latent Dirichlet allocation,” J. Mach. Learn. Res., vol. 3, pp. 993–1022, Jan. 2003.